C: 穿越时空的迷雾
它很棒,但它符合标准吗
不可移植代码
不同编译器定义不同的行为
未定义行为
标准中未规定的行为,这种行为编译器可以自己随意解释
可移植的代码
严格遵循标准的代码:只使用已确定的特性、不突破任何由编译器实现的限制、不产生任何依赖由编译器定义的或未确定的或未定义的特性的输出。
编译限制
ANSI C编译器需要支持:
函数定义中形参数量的上限至少可以达到31个
函数调用时实参数量的上限至少可以达到31个
在一条源代码行里至少可以有509个字符
在表达式中至少可以支持32层嵌套的括号
long int的最大值不得小于2147483647(不得低于32位)
以上的这些并不是约束条件,也就是说当编译器发现违反了这些条件也不会报错。
阅读ANSI C标准
赋值形式合法,必须满足下列条件之一:
两个操作数都是指向有限定符或者没有限定符的相容类型的指针;左边的指针所指向的类型必须具有右边的指针所指向的类型的全部限定符。
Both operands are pointers to qualified or unqualified versions of compatible types, and the type pointed to by the left has all the qualifiers of the type pointed to by the right.
const char ** p是一个指向char *类型的常量指针(常量指针也就是char *这个指针是一个常量不能被修改)。
const用来限定函数的形参,进行限定之后该函数就不会修改实参指针所指向的数据,但是其他的函数却可能会修改它。
“安静的改变”究竟有多少安静
1 2 3 4 5 6 7 8 9 10 int array [] = { 23 , 34 , 12 , 17 , 204 , 99 , 16 };#define TOTAL_ELEMENTS (sizeof(array) / sizeof(array[0])) main() { int d= -1 , x; if (d <= TOTAL_ELEMENTS-2 ) x = array [d+1 ]; }
在ANSI C中因为sizeof返回一个unsigned int类型,在if语句中d被升级为unsigned int类型(Otherwise, if either operand has type unsigned int, the other operand is converted to unsigned int),因此它编程了一个非常巨大的正整数,致使表达式的值为假。
Ada是什么?
Ada is a structured, statically typed, imperative, and object-oriented high-level programming language, extended from Pascal and other languages.
这不是Bug,而是语言特性
fall through
case语句不加break的时候,就会依次执行下去。
break不会跳出if语句,而是会 跳出最近的那层循环语句或者switch语句。
相邻的字符串会自动合并,例如
1 2 3 s = "hello world!" "you are welcome" ;
者在字符串数组初始化的时候会引来错误信息。
下面的程序会使得第一次调用generate_initializer和之后调用它得到的结果不同。第一次会以,开头。
1 2 3 4 5 6 generate_initializer(char * string ) { static char separator=''; printf ( "%c %s \n" , separator, string ); separator = ',' ; }
多做之过
在缺省的情况下函数的名字是全局可见的,可以在函数的名字前添加extern关键词,实际上没有添加这个关键词也是一样的效果,假如要限制这个函数的可见性则要使用关键词static进行修饰。
1 static function turnip ()
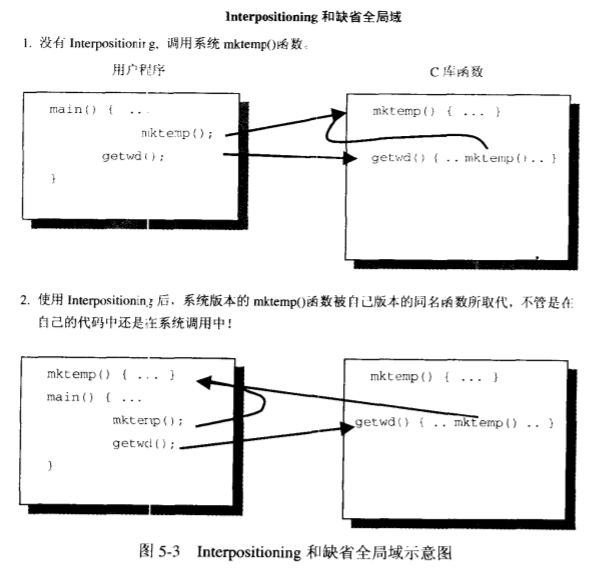
该特性会与C语言的另外一个特性组合起来造成影响。另一个特性叫做interpositioning,该特性允许用户编写和库函数同名的函数并取而代之。
C语言中对于一个函数你只能选择它是全局可见还是全局不可见,而不能指定对哪些文件可见对哪些不可见。也就是all-or-nothing
误做之过
在上述表达式中,乘法一定会在加法之前进行,但是不能确定的是f(),g(),h()的计算顺序,它们之间以任何顺序进行都是合法的。
少做之过
就是指语言应该提供但是没有提供的特性。
C语言中不能返回局部变量,因为局部变量通常分配在栈中,所以返回之后只是返回一个指向栈的地址,谁也不知道那个地址上会存什么内容。
解决这个问题的方案:
返回一个指向字符串常量的指针
使用全局声明的数组
使用静态数组 static char buffer[20];
显式分配一些内存,保存返回的值 char * s = malloc(120);
最好的解决方案就是要求调用者分配内存来保存函数的返回值。为了提高安全性,调用者应该同时指定缓冲区的大小。
1 2 3 4 5 6 7 8 void func ( char * result, int size ) strncpy (result,"That'd be in the data segment, Bob" ,size );} buffer = malloc (size );func( buffer , size ); ... free (buffer );
分析C语言的声明
声明是如何形成的
枚举
枚举(enum)将一串名字与一串整型值联系在一起。
#define定义的名字一般在编译时被丢弃,而枚举名字则通常一直在调试器中可见,可以在调试代码时使用它们。
通过图表分析C语言的声明
char * const * (*next)(); next是一个指向函数的指针,该函数返回另一个指针,该指针指向一个只读的指向char的指针
char * (* c[10])(int **p); c是一个数组[0..9],它的元素类型是函数指针,其所指向的函数的返回值是一个指向char的指针
typedef可以成为你的朋友
一般情况下,typedef用于简洁地表示指向其他东西的指针。
void (*func)(int);它表示一个函数指针,所指向的函数接受一个int参数,返回值是void
void(*signal())(int)其中signal是一个函数,它返回一个函数指针,然后这个函数指针所指向的函数接受一个int参数并返回void
typedef声明别名之后不能进行扩展:
1 2 typedef int banana;unsigned banana i;
理解所有分析过程的代码段
设计方案:使用一个堆栈,从左向右读取,把每个标记依次压入堆栈,直到读到标识符为止。然后我们继续向右读入一个标记,也就是标识符右边的那个标记。接着,观察标识符左边的那个标记(该标记需要从弹出)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 #include <ctype.h> #include <stdio.h> #include <string.h> #include <stdlib.h> #define MAXTOKENLEN 64 #define MAXTOKENS 32 enum type_tag{ TYPE, QUALIFIER, IDENTIFIER};struct token { char type; char string [MAXTOKENLEN]; }; int top = -1 ;struct token stack [MAXTOKENS ];struct token this_token ;#define pop() stack[top--] #define push(s) stack[++top] = s enum type_tag classify_string (void ) char *s = this_token.string ; if (strcmp (s, "const" ) == 0 ) { strncpy (s, "只读" , 5 ); return QUALIFIER; } if (strcmp (s, "volatile" ) == 0 ) { return QUALIFIER; } if (strcmp (s, "void" ) == 0 ) { return TYPE; } if (strcmp (s, "char" ) == 0 ) { return TYPE; } if (strcmp (s, "signed" ) == 0 ) { return TYPE; } if (strcmp (s, "unsigned" ) == 0 ) { return TYPE; } if (strcmp (s, "short" ) == 0 ) { return TYPE; } if (strcmp (s, "int" ) == 0 ) { return TYPE; } if (strcmp (s, "long" ) == 0 ) { return TYPE; } if (strcmp (s, "float" ) == 0 ) { return TYPE; } if (strcmp (s, "double" ) == 0 ) { return TYPE; } if (strcmp (s, "struct" ) == 0 ) { return TYPE; } if (strcmp (s, "union" ) == 0 ) { return TYPE; } if (strcmp (s, "enum" ) == 0 ) { return TYPE; } return IDENTIFIER; } void get_token (void ) char *p = this_token.string ; while ((*p = getchar()) == ' ' ) { ; } if (isalnum (*p)) { while (isalnum (*++p = getchar())) { ; } ungetc(*p, stdin ); *p = '\0' ; this_token.type = classify_string(); return ; } if (*p == '*' ) { strncpy (this_token.string , "指针,该指针指向" , 17 ); this_token.type = '*' ; return ; } this_token.string [1 ] = '\0' ; this_token.type = *p; return ; } void read_to_first_identifier (void ) get_token(); while (this_token.type != IDENTIFIER) { push(this_token); get_token(); } printf ("%s是" , this_token.string ); get_token(); return ; } void deal_with_function_args (void ) while (this_token.type != ')' ) { get_token(); } get_token(); printf ("函数,该函数返回" ); } void deal_with_arrays (void ) while (this_token.type == '[' ) { get_token(); printf ("数组" ); if (isdigit (this_token.string [0 ])) { printf ("0..%d" , atoi(this_token.string ) - 1 ); get_token(); } printf (",该数组类型是" ); } } void deal_with_pointers () while (stack [top].type == '*' ) { printf ("%s" , pop().string ); } } void deal_with_declarator () switch (this_token.type) { case '[' : deal_with_arrays(); break ; case '(' : deal_with_function_args(); break ; } deal_with_pointers(); while (top >= 0 ) { if (stack [top].type == '(' ) { pop(); get_token(); deal_with_declarator(); } else { printf ("%s " , pop().string ); } } } int main () read_to_first_identifier(); deal_with_declarator(); printf ("\n" ); system("pause" ); return 0 ; }
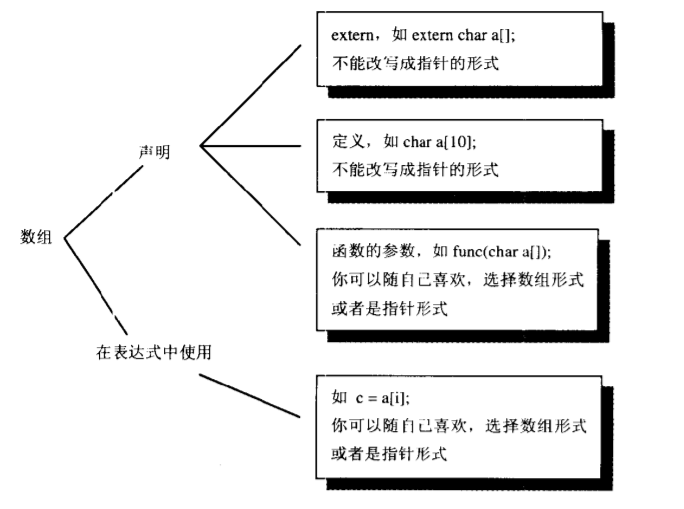
令人震惊的事实:数组和指针并不相同
确实存在一种指针和数组的定义完全相同的上下文环境,但是这只是数组的一种极为普通的用法,并非所有情况下都是如此。
什么是定义,什么是声明
C语言中的对象必须 有且只有一个定义,但是它可以有多个extern声明。定义是一种特殊的声明,它创建了要给对象,而声明只是告诉我们在其他的地方创建过这个对象,把那个对象的名字重新说一遍,并允许你使用这个名字。所谓定义就是要为该对象分配内存。
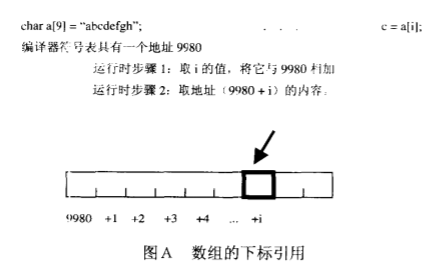
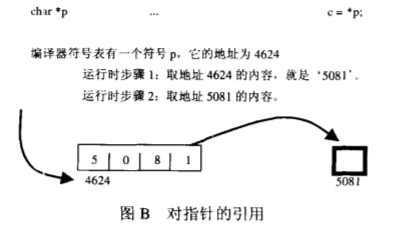
使用指针需要多一个额外的提取,但是它更加灵活。
1 char *p = "abcdefgh" ; ... p[3 ];
取得符号表中的p的地址,提取存储于此处的指针
把下标所表示的偏移量与指针的值相加,从而得到一个新地址
访问上面的这个地址,取得字符
使用指针初始化的字符串,通常会被放在只读的文本段中。但是由字符串常量初始化的数组是可以被修改的。其中的单个字符在以后可以改变。
对链接的思考
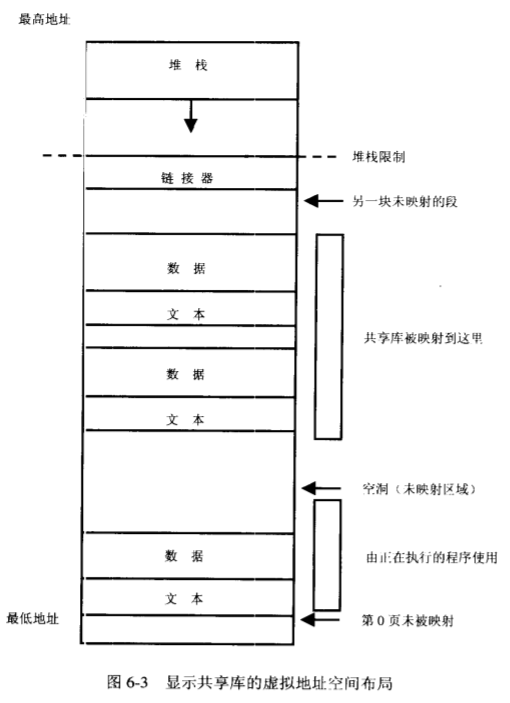
动态链接
动态链接必须保证4个特定的函数库libc(C运行时函数库)、libsys(其他系统函数)、libX(X windowing)、libnsl(网络服务)
静态库使用ar进行链接,动态库使用ld进行链接。
.so表示shared object,是动态库文件的扩展名
.a是静态库文件的扩展名
可以通过选项告诉编译应该链接的函数库的完整名称,例如-lthread表示编译连接到libthread.so,-lname表示链接到libname.so
编译器-Lpathname和-Rpathname用来告诉链接器一些其他的目录。
在缺省状态下链接器会在/usr/ccs/lib和/usr/lib中查找函数库中的符号
函数库选项:应该始终将-l函数库选项放在编译命令行的最右边
警惕Interposition
Interposition也就是使用同样名称的用户函数去代替标准的库函数
产生链接器报告文件
在ld程序中使用-m选项,会让链接器产生一个报告。该报告包括了被Interpose的符号的说明。
ld程序 中的-D允许用户显示链接-编辑过程和所包含的输入文件。
运动的诗章:运行时数据结构
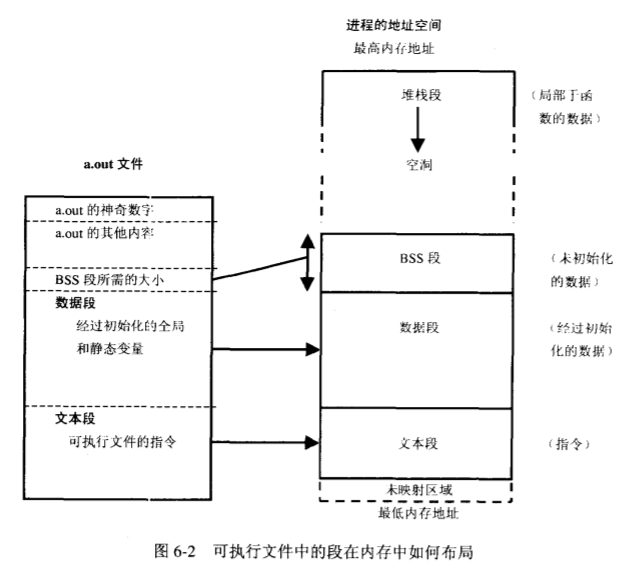
a.out: assembler output
数据段保存在目标文件中
ss段不保存在目标文件中(除了记录BSS段在运行时所需的大小)
文本段最容易收到优化措施影响
a.out文件的大小受调试状态下编译的影响,但段不受影响
操作系统在a.out文件里干了些什么
auto和static关键字
使用static关键字,那么变量就会被分配在数据段中,而不是在堆栈中。auto表示在进入该块后,自动分配存储,在函数的内部声明的数据默认就是这种分配方式,它几乎不在实际中使用。
控制线程
在进程中要支持不同的控制线程依赖的是使用不同的堆栈,每个线程的堆栈为1Mb(当有需要的时候可以增长)在每个线程的堆栈之间有个一个red zone页。(这个红色区域(red zone)就是一个优化。因为这个区域不会被信号或者中断侵占,函数可以在不移动栈指针的情况下使用它存取一些临时数据——于是两个移动rsp的指令就被节省下来了)
setjmp和longjmp
会使用setjmp来设置一个需要跳转的label,然后使用longjmp来跳转。它相比goto可以跳转到更远的地方,goto只能在函数内部跳转。需要使用头文件<setjmp.h>
对内存的思考
所有的磁盘制造商都是使用十进制数而不是二进制数来表示磁盘的容量。2GB是2000000000个字节而不是217483648个字节
虚拟内存
交换区在磁盘上,一般而言交换区的大小是物理内存的几倍。内核是常驻内存的,一般只有用户进程才会被换进换出。
Cache存储器
Cache的操作速度与系统的周期时间相同。因此50MHz的处理器,Cache的存取周期为20ns。
内存泄漏
可以使用alloca()来分配动态内存,但是该方法不适合在生命期更长的结构中使用。
在链表中释放元素
1 2 3 4 5 struct node *p , *start , *tmp ;for (p = start; p; p = tmp){ tmp = p -> next; free (p); }
sign.h有什么用?
https://en.wikipedia.org/wiki/C_signal_handling
为什么程序员无法分清万圣节和圣诞节
在等待时类型发生了变化
参数也会被提升
在被调用函数的内部,提升后的参数会被裁减为原先声明的大小。例如在使用printf的时候,%d会默认取出int类型的参数,也就是说假如使用它去打印long long的值则会发生问题。
原型之痛
建立原型的目的就是消除一种普通(但是很难被发现)的错误,就是形参和实参之间类型不匹配。
int ioctl(int fd, ind cmd, …); 其中fd是用户程序打开设备时使用open函数返回的文件标示符,cmd是用户程序对设备的控制命令,至于后面的省略号,那是一些补充参数,一般最多一个,这个参数的有无和cmd的意义相关。 ioctl函数是文件结构中的一个属性分量,就是说如果你的驱动程序提供了对ioctl的支持,用户就可以在用户程序中使用ioctl函数来控制设备的I/O通道。
用C语言实现有限状态机
大多是有限状态机基于函数指针数组。
1 2 3 4 5 void (*state[MAX_STATES])();extern int a(), b(), c(), d(); int (*state[])() = { a, b, c, d }; (*state[i])();
cdecl as an FSM
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 #include <stdio.h> #include <string.h> #include <ctype.h> #define MAXTOKENS 100 #define MAXTOKENLEN 64 enum type_tag { IDENTIFIER, QUALIFIER, TYPE };struct token { char type; char string [MAXTOKENLEN]; }; int top = -1 ;struct token stack [MAXTOKENS ];struct token this ;#define pop stack[top--] #define push(s) stack[++top]=s enum type_tagclassify_string(void ) { char *s = this .string ; if (!strcmp (s, "const" )) { strcpy (s, "read-only" ); return QUALIFIER; } if (!strcmp (s, "volatile" )) return QUALIFIER; if (!strcmp (s, "void" )) return TYPE; if (!strcmp (s, "char" )) return TYPE; if (!strcmp (s, "signed" )) return TYPE; if (!strcmp (s, "unsigned" )) return TYPE; if (!strcmp (s, "short" )) return TYPE; if (!strcmp (s, "int" )) return TYPE; if (!strcmp (s, "long" )) return TYPE; if (!strcmp (s, "float" )) return TYPE; if (!strcmp (s, "double" )) return TYPE; if (!strcmp (s, "struct" )) return TYPE; if (!strcmp (s, "union" )) return TYPE; if (!strcmp (s, "enum" )) return TYPE; return IDENTIFIER; } void gettoken (void ) char *p = this .string ; while ((*p = getchar()) == ' ' ); if (isalnum (*p)) { while (isalnum (*++p = getchar())); ungetc(*p, stdin ); *p = '\0' ; this .type = classify_string(); return ; } this .string [1 ] = '\0' ; this .type = *p; return ; } void initialize(), get_array(), get_params(), get_lparen(), get_ptr_part(), get_type(); void (*nextstate)(void ) = initialize; int main () while (nextstate != NULL ) (*nextstate)(); return 0 ; } void initialize () gettoken(); while (this .type != IDENTIFIER) { push(this ); gettoken(); } printf ("%s is " , this .string ); gettoken(); nextstate = get_array; } void get_array () nextstate = get_params; while (this .type == '[' ) { printf ("array " ); gettoken(); if (isdigit (this .string [0 ])) { printf ("0..%d " , atoi(this .string ) - 1 ); gettoken(); } gettoken(); printf ("of " ); nextstate = get_lparen; } } void get_params () nextstate = get_lparen; if (this .type == '(' ) { while (this .type != ')' ) { gettoken(); } gettoken(); printf ("function returning " ); } } void get_lparen () nextstate = get_ptr_part; if (top >= 0 ) { if (stack [top].type == '(' ) { pop; gettoken(); nextstate = get_array; } } } void get_ptr_part () nextstate = get_type; if (stack [top].type == '*' ) { printf ("pointer to " ); pop; nextstate = get_lparen; } else if (stack [top].type == QUALIFIER) { printf ("%s " , pop.string ); nextstate = get_lparen; } } void get_type () nextstate = NULL ; while (top >= 0 ) { printf ("%s " , pop.string ); } printf ("\n" ); }
debugging hooks:可以编写一个函数用于遍历整个数据结构并把它打印出来,然后可以在调试的时候通过调试器命令行来调用该函数。
可调式性编码:先完成最简单的功能,然后逐步增加更加复杂的功能。
混乱代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <stdio.h> #include <ctype.h> #define w printf #define p while #define t(s) (W=T(s)) char *X,*B,*L,I[99 ];M,W,V;D(){W==9 ?(w("`%.*s' is" ,V,X),t(0 )):W==40 ?(t(0 ),D(),t(41 )):W==42 ?(t(0 ),D(),w("ptr to " )):0 ;p(W==40 ?(t(0 ), w("func returning " ),t(41 )):W==91 ?(t(0 )==32 ?(w("array[0..%d] of " ,atoi(X)-1 ),t(0 )):w("array of " ),t(93 )):0 );}main(){p(w("input: " ),B=gets(I))if (t(0 )==9 )L=X,M=V,t(0 ),D(),w("%.*s.\n\n" ,M,L);}T(s) {if (!s||s==W) {p(*B==9 ||*B==32 )B++;X=B;V=0 ;if (W=isalpha (*B)?9 :isdigit (*B)?32 :*B++) if (W<33 )p(isalnum (*B))B++,V++;}return W;}
该程序也就是之前的cdel程序,首先有两个子程序T()和D(),前者用来寻找下一个标记并确定它是标识符、数字还是其他东西,后者负责分析过程。三元符需要还原成if语句才能使该程序可读。
再论数组
什么时候数组与指针相同
为什么会发生混淆
数组下标表达式总是可以改写为带偏移量的指针表达式。作为函数的参数的时候数组和指针是可以互换的,以及在表达式中它们是可以互换的。在表达式中a[10]很可能被翻译成*(a+i)
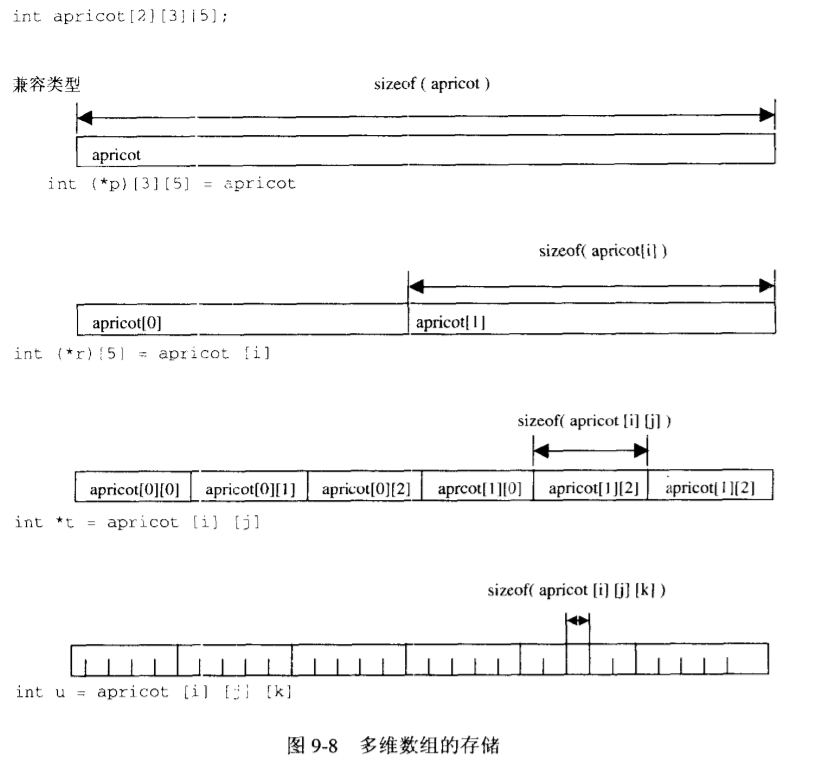
多维数组
1 2 3 char carrot[i][j];*(*(carrot + i) + j);
只有字符串常量才可以初始化指针数组。
%#x 什么意思?
The character % is followed by zero or more of the following flags:
# The value should be converted to an ‘‘alternate form’’. For o conversions, the first character of the output string is made zero (by prefixing a 0 if it was not zero already). For x and X conversions, a non-zero result has the string ‘0x’ (or ‘0X’ for X conversions) prepended to it. For a, A, e, E, f, F, g, and G conversions, the result will always contain a decimal point, even if no digits follow it (normally, a decimal point appears in the results of those conversions only if a digit follows). For g and G conversions, trailing zeros are not removed from the result as they would otherwise be. For other conversions, the result is undefined.
再论指针
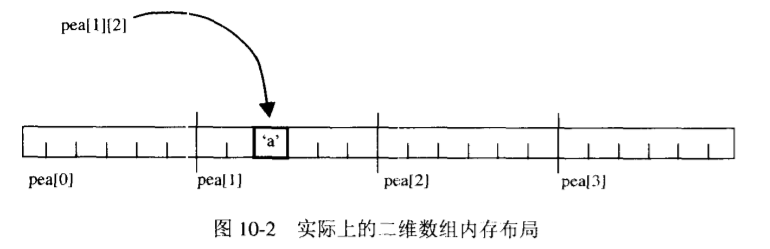
多维数组的内存布局
在锯齿状数组上使用指针
假如要保存的字符串长度不一,可以使用字符串指针数组来解决。